
TL;DR
Building a resilient architecture, it could help to separate systems along the control and data plane boundary. Once separated, focus on the data plane for targeting a higher availability. Because of its relative simplicity, a data plane is much better suited for High Availability than a control plane. Finally, introduce static stability by preparing yourself for impairments before they happen. Don’t rely on reacting to impairments as they happen, it’s less effective. A statically stable design is achieved once the overall system keeps working, even when a dependency becomes impaired!
Very recently, while browsing some online AWS documentation, I landed on a page about Static stability using Availability Zones. Although that page had nothing to do with what I was looking after, I found the title quite intriguing. I had never heard about the concept before. Triggered, I decided to read the paper. It turned out to be one of the more interesting papers I’ve read in a while. The remainder of this post is a brief rehash of the paper, focussed on the core concept and supplemented with my thoughts.
Important note: although the paper originates from AWS, the concepts are not limited to the AWS Ecosystem but are broadly applicable in system design.
Before we start
Because static stability is all about resilience, I need once more to rant a little on the importance of RTO and RPO first. I find it hard to understand that sometimes systems are being designed without knowing their recovery objectives. It seems impossible to make a great design without knowing these. A design that doesn’t consider the recovery objectives from the start will inevitably result in over-or underengineering.
Always sort out the recovery objectives first before starting a system design!
What is Static Stability?
In a statically stable design, the overall system keeps working even when a dependency becomes impaired. Perhaps the system doesn’t see any updated information that its dependency was supposed to have delivered. However, everything it was doing before the dependency became impaired continues to work despite the impaired dependency.
Before we drill further down, we first need to talk about Availability Zones, because on AWS, availability zones are a main pillar of statically stable designs. Therefore a quick refresher of the definition of an Availably Zone: “an Availability Zone is one or more discrete data centers with redundant power, networking, and connectivity in an AWS Region”.
Over the years, when building systems on top of Availability Zones, AWS has learned to be ready for impairments before they happen. A less effective approach might be to deploy to multiple Availability Zones with the expectation that, should there be an impairment within one Availability Zone, the service will scale up in other Availability Zones and be restored to full health. This approach is less effective because it relies on reacting to impairments as they happen, rather than being prepared for those impairments before they happen. In other words, it lacks static stability. In contrast, a more effective, statically stable service would over-provision its infrastructure to the point where it would continue operating correctly without having to launch anything new, even if an Availability Zone were to become impaired.
However, understanding static stability itself is only half the story. To properly apply the pattern to a system design, you need to understand a second concept: control and data planes.

What is a Control and Data plane?
A control plane is the machinery involved in making changes to a system (adding resources, deleting resources, modifying resources) and getting those changes propagated to wherever they need to go to take effect. A data plane, in contrast, is the daily business of those resources, that is, what it takes for them to function. Furthermore, It’s crucial to understand that the data plane is usually far simpler than its control plane. As a result of its relative simplicity, a data plane is much better suited for targeting a higher availability than a control plane.
Putting it all together
Separate systems along the control and data plane boundary
The concepts of control planes, data planes, and static stability are broadly applicable in various system designs. Suppose you’re able to decompose a system into its control plane and data plane. In that case, it might be a helpful conceptual tool for designing highly available services for several reasons:
- It’s typical for the availability of the data plane to be even more critical to the success of the customers of a service than the control plane.
- It’s typical for the data plane to operate at a higher volume (often by orders of magnitude) than its control plane. Thus, it’s better to keep them separate so that each can be scaled according to its own relevant scaling dimensions.
- AWS found over the years that a system’s control plane tends to have more moving parts than its data plane, so it’s statistically more likely to become impaired for that reason alone.
Putting those considerations altogether, it seems a best practice to separate systems along the control and data plane boundary.
Now, let’s zoom in on some examples of Static Stable Designs.
Design 1: Static Stability using an Active-Active setup on Availability Zones
A common example of an active-active design on AZ’s is a load-balanced HTTPS service. The diagram below shows a public-facing Load Balancer providing an HTTPS service. The load balancer’s target is an Auto Scaling group that spans three Availability Zones. This is an example of active-active high availability using Availability Zones.
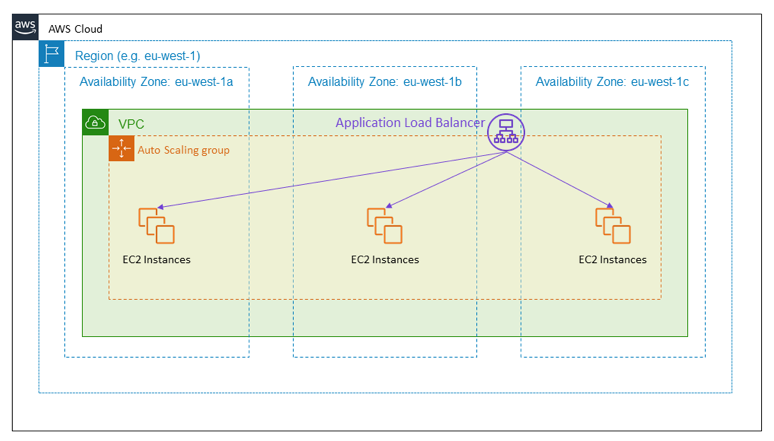
In the event of an Availability Zone impairment, this design requires no action. The instances in the impaired Availability Zone will start failing health checks, and the Load Balancer will shift traffic away from them.
Design 2: Static Stability using an Active-standby on Availability Zones
The next diagram shows an Amazon RDS database. In this case, the RDS database setup spans multiple Availability Zones. In a multi-AZ setup Amazon RDS puts the standby candidate in a different Availability Zone from the primary node. In this setup, when the Availability Zone with the primary node becomes impaired, the stateful service does nothing with the infrastructure. In the background, RDS will manage the failover and then repoint the DNS name to the new primary in the working Availability Zone.
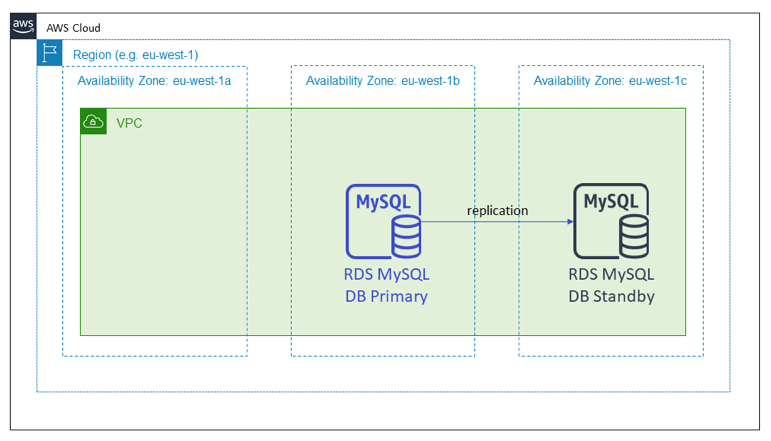
These two patterns have in common that both of them had already provisioned the capacity they’d need in the event of an Availability Zone impairment well in advance of any actual impairment.
The principle of independent Availability Zones
A third way to use the principle of independent Availability Zones is to design a packet flow to stay within an Availability Zone rather than crossing boundaries. Keeping network traffic local to the Availability Zone is worth exploring in more detail. The following diagram illustrates a highly available external service, shown in orange, that depends on another, internal service, shown in green. A straightforward design treats both of these services as consumers of independent EC2 Availability Zones. Each of the orange and green services is fronted by a Load Balancer, and each service has a well-provisioned fleet of backend hosts spread across three Availability Zones. One highly available regional service calls another highly available regional service. This is a simple design, and for many of the services we’ve built, it’s a good design.
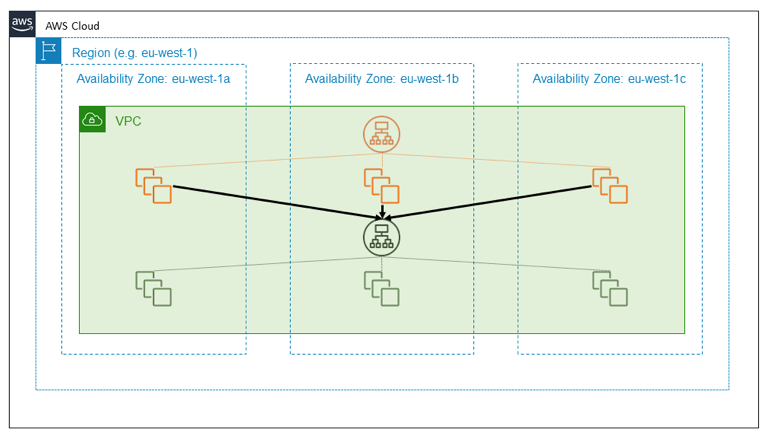
Suppose, however, that the green service is a foundational service. That is, suppose it is intended not only to be highly available but also, itself, to serve as a building block for providing Availability Zone independence. In that case, you might instead design it as three instances of a zone-local service, on which we follow Availability Zone-aware deployment practices. The following diagram illustrates the design in which a highly available regional service calls a highly available zonal service.
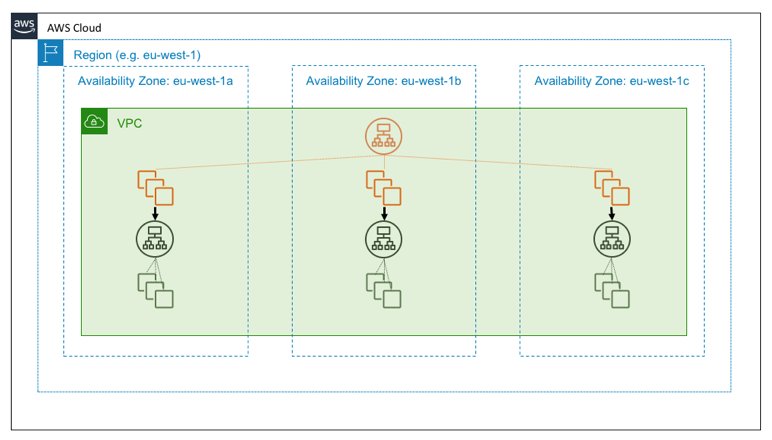
The reasons to design a building-block service to be Availability Zone independent comes down to simple arithmetic.
In a system where one highly available regional service calls another highly available regional service and a request is sent through the system, then with some simplifying assumptions, the chance of the request avoiding the impaired Availability Zone is 2/3 * 2/3 = 4/9. That is, the request has worse than even odds of steering clear of the event.
In contrast, if you built the green service to be a zonal service, then the hosts in the orange service can call the green endpoint in the same Availability Zone. With this architecture, the chances of avoiding the impaired Availability Zone are 2/3. If N services are a part of this call path, then these numbers generalize to (2/3)^N for N regional services versus remaining constant at 2/3 for N zonal services!
I hope you enjoyed reading about the concept of static stability and the principles of independent AZ’s as much as I did. 😉
Kudos to Becky Weiss and Mike Furr, the authors of the original AWS paper about Static Stability.
Until next time!